在過去 8 個月中,高通對其高性能 Windows-on-Arm SoC 做出了許多有趣的聲明,其中許多將在未來幾周接受測試?但在 PC CPU 競爭日益激烈的環(huán)境中,除了所有性能聲明和宣傳之外,還有一個關(guān)于驍龍 X 的更基本的問題,我們一直渴望知道:它是如何工作的?
在下周發(fā)布之前,我們終于得到了答案,因為今天高通發(fā)布了他們期待已久的驍龍 X SoC 架構(gòu)披露?這不僅包括他們新的定制 Arm v8“Oryon”CPU 核心,還包括他們的 Adreno GPU 的技術(shù)披露,以及支持他們大力推廣的 AI 功能的 Hexagon NPU?
該公司過去曾明確表示,驍龍 X 是該公司的一項嚴(yán)肅?優(yōu)先的計劃——他們不會只是將現(xiàn)有的 IP 模塊拼湊成 Windows SoC 就完事了——因此 SoC 中有很多新技術(shù)?

雖然我們很高興看到這一切,但我們首先要承認(rèn),我們最興奮的是終于能夠深入了解 Oryon,即高通定制的 Arm CPU 內(nèi)核?作為過去幾年中第一個從頭開始創(chuàng)建的新型高性能 CPU 設(shè)計,Oryon 的重要性怎么強(qiáng)調(diào)都不為過?除了為新一代 Windows-on-Arm SoC 提供基礎(chǔ)(高通希望借此在 Windows PC 市場上占據(jù)一席之地)之外,Oryon 還將成為高通傳統(tǒng)驍龍移動手機(jī)和平板電腦 SoC 的基礎(chǔ)?
因此,未來幾年,該公司的大量硬件都將基于這種 CPU 架構(gòu)——如果一切按計劃進(jìn)行,Oryon 將會推出更多代產(chǎn)品?不管怎樣,它都會讓高通在 PC 和移動領(lǐng)域都從競爭對手中脫穎而出,因為這意味著高通正在擺脫 Arm 的參考設(shè)計,而 Arm 的參考設(shè)計本質(zhì)上也是高通的競爭對手?
事不宜遲,讓我們深入了解高通的驍龍 X SoC 架構(gòu)?
Elite?Plus 和當(dāng)前已發(fā)布的 SKU
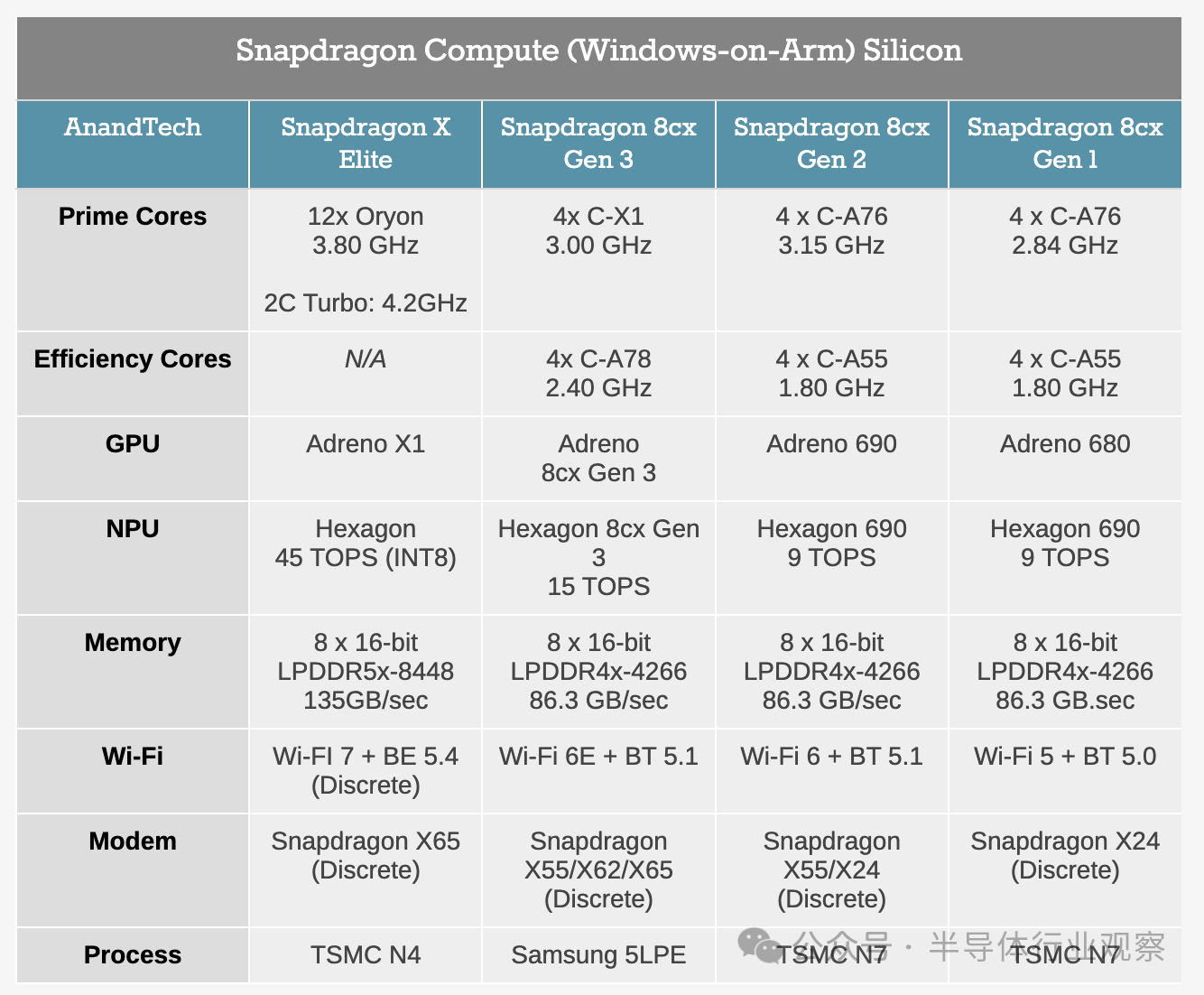
簡單回顧一下,高通迄今已宣布了 4 款 Snapdragon X SKU,所有產(chǎn)品均已提供給設(shè)備制造商,將于下周推出?

其中三款是“Elite”SKU,即包含 12 個 CPU 核心?與此同時,高通目前只推出了一款“Plus”SKU,其 CPU 核心數(shù)量減少至 10 個?
官方稱,高通并未為這些芯片 SKU 指定任何 TDP 等級,因為原則上,任何給定的 SKU 都可以在整個功率水平范圍內(nèi)使用?需要在無風(fēng)扇筆記本電腦中安裝頂級芯片?只需調(diào)低 TDP 以匹配您的電源/冷卻能力即可?也就是說,要達(dá)到高通芯片的最高時鐘速度和性能目標(biāo),需要大量的冷卻和電力輸送?為此,我們不太可能看到 X1E-84-100 出現(xiàn)在無風(fēng)扇設(shè)備中,例如,因為它的較高時鐘速度會因缺乏散熱空間而大量浪費?這不會阻止性能較低的芯片作為預(yù)算選項用于更大的設(shè)備,但 SKU 表也可以被視為大致按 TDP 排序?
雖然這不是今天披露的內(nèi)容,但看到更多驍龍 X 芯片 SKU 即將推出,也不要感到驚訝?高通至少還有一款驍龍 X 芯片正在開發(fā)中,這已經(jīng)成為一個鮮為人知的秘密——一款尺寸更小?CPU 和 GPU 核心可能更少的芯片——未來可能會推出更注重預(yù)算的 SKU 系列?但目前,高通正從其大芯片開始,因此也是其性能最高的選擇?
盡管首批 Snapdragon X 設(shè)備要到下周才會與消費者見面,但從 OEM 采用情況來看,這顯然將是高通迄今為止最成功的 Windows-on-Arm SoC?與 Snapdragon 8cx Gen 3 相比,采用情況的差異幾乎是天壤之別;高通的 PC 合作伙伴已經(jīng)使用新芯片開發(fā)了十幾款筆記本電腦型號,而最新的 8cx 則有兩種設(shè)計?因此,隨著微軟?戴爾?惠普?聯(lián)想等公司都在生產(chǎn) Snapdragon X 筆記本電腦,Snapdragon X 生態(tài)系統(tǒng)的起步比之前的任何 Windows-on-Arm 產(chǎn)品都要強(qiáng)大得多?
毫無疑問,這很大程度上歸功于高通架構(gòu)的強(qiáng)大?驍龍 X 搭載了高通宣稱比最新(大約 2022 年)8cx 芯片上的 Cortex-X1 內(nèi)核強(qiáng)大得多的 CPU,并且采用與臺積電 N4 節(jié)點高度競爭的工藝制造?因此,如果所有條件都正確,驍龍 X 芯片對高通來說應(yīng)該是一個巨大的進(jìn)步?
同時,還有另外兩個支柱支撐著這款產(chǎn)品的發(fā)布?第一個當(dāng)然是人工智能,驍龍 X 是首款支持 Copilot+ 的 Windows SoC?驍龍 X 的 Hexagon NPU 需要 40+ TOPS NPU,45 TOPS 的 Hexagon NPU 使這款 SoC 成為首款為神經(jīng)網(wǎng)絡(luò)和其他模型推理提供如此高性能的芯片?第二個支柱是性能?高通承諾,憑借其多年生產(chǎn)移動 SoC 的經(jīng)驗,其 SoC 的電池續(xù)航時間將非常長?如果他們能夠?qū)崿F(xiàn)這一目標(biāo),同時實現(xiàn)性能目標(biāo)——讓用戶魚與熊掌兼得——那么它將為驍龍 X 芯片和由此產(chǎn)生的筆記本電腦提供良好的基礎(chǔ)?

最終,高通希望實現(xiàn)他們的 Apple Silicon 時刻——重復(fù)蘋果從英特爾 x86 芯片轉(zhuǎn)向他們自己的定制 Arm 芯片 Apple Silicon 時獲得的性能和電池壽命提升?而合作伙伴微軟則非常非常希望在 PC 生態(tài)系統(tǒng)中擁有 MacBook Air 的競爭對手?這是一項艱巨的任務(wù),其中最重要的原因是英特爾和 AMD 在過去幾年中都沒有停滯不前,但這并非遙不可及?
話雖如此,高通和 Windows-on-Arm 生態(tài)系統(tǒng)確實面臨一些障礙,這意味著驍龍 X 的發(fā)布軌跡永遠(yuǎn)無法與蘋果相提并論?除了明顯缺乏一個統(tǒng)一的開發(fā)硬件和軟件生態(tài)系統(tǒng)的一方(以及推動開發(fā)人員為其開發(fā)軟件之外),Windows 還帶有向后兼容的期望,以及由此帶來的遺留包袱?微軟方面則繼續(xù)致力于其 x86/x64 仿真層,現(xiàn)在名為 Prism,而驍龍 X 的發(fā)布將是它第一次真正接受考驗?但即使 Windows 多年來一直支持 Arm,軟件生態(tài)系統(tǒng)仍在慢慢成形,因此驍龍 X 將比蘋果更依賴 x86 仿真?Windows 和 macOS 是非常不同的操作系統(tǒng),無論是從它們的歷史還是所有者的開發(fā)理念來看,這在驍龍 X 的頭幾年尤其明顯?
Oryon CPU 架構(gòu):一個為所有應(yīng)用精心設(shè)計的核心
為了深入研究架構(gòu),我們將從最核心的部分開始:Oryon CPU 核心?
簡單回顧一下,Oryon 本質(zhì)上是高通的第三方收購?該 CPU 核心最初名為“Phoenix”,由芯片初創(chuàng)公司 NUVIA 開發(fā)?NUVIA 本身由多位前蘋果員工組成,其最初的計劃是開發(fā)一種新的服務(wù)器 CPU 核心,該核心將與現(xiàn)代 Xeon?EPYC 和 Arm Neoverse V CPU 中的核心競爭?
然而,高通抓住了獲得優(yōu)秀 CPU 開發(fā)團(tuán)隊的機(jī)會,于 2021 年收購了 NUVIA?Phoenix被重新用于消費級硬件,重生為 Oryon CPU 核心?
雖然高通并沒有過多關(guān)注 Oryon 的根源,但很明顯,第一代架構(gòu)(采用 Arm 的 v8.7-A ISA)仍然深深植根于最初的 Phoenix 設(shè)計?Phoenix 本身已經(jīng)設(shè)計為可擴(kuò)展且節(jié)能,因此這對高通來說絕不是壞事?但這確實意味著有許多以客戶為中心的核心設(shè)計變化沒有出現(xiàn)在最初的 Oryon 設(shè)計中,我們應(yīng)該期待在未來幾代 CPU 架構(gòu)中看到這些變化?

深入研究后,正如高通先前披露的那樣,驍龍 X 使用了三組 Oryon CPU 核心?從高層次來看,Oryon 被設(shè)計為全尺寸 CPU 核心,能夠同時提供能效和性能?為此,它是高通所需的唯一 CPU 核心;它并沒有像高通之前的驍龍 8cx 芯片或英特爾/AMD 最新的移動芯片那樣,單獨設(shè)置性能優(yōu)化和效率優(yōu)化的核心?
據(jù)高通披露,所有集群都是平等的?因此,沒有一個“效率”集群針對電源效率而非時鐘速度進(jìn)行調(diào)整?不過,只有 2 個 CPU 內(nèi)核(在不同的集群中)可以達(dá)到任何給定 SKU 的最高渦輪增壓速度;其余內(nèi)核的最高速度達(dá)到芯片的全核渦輪增壓速度?
而每個集群又有自己的 PLL,因此每個集群都可以單獨計時和通電?實際上,這意味著在工作量較少時,兩個集群可以進(jìn)入休眠狀態(tài),然后在需要更多性能時從休眠狀態(tài)喚醒?

與大多數(shù) CPU 設(shè)計不同,高通為 Snapdragon X 和 Oryon CPU 核心集群采用了更扁平的緩存層次結(jié)構(gòu)?L2 緩存不是每個核心都有一個緩存,而是每 4 個核心共享一個緩存(這與英特爾在其 E 核心集群上共享 L2 緩存的方式非常相似)?而且,這也是一個相當(dāng)大的 L2 緩存,大小為 12MB?L2 緩存是 12 路關(guān)聯(lián)的,即使如此大,在 L1 未命中后訪問 L2 緩存的延遲也只有 17 個周期?
這是一個包容性緩存設(shè)計,因此它也包含 L1 緩存中內(nèi)容的鏡像?據(jù)高通稱,他們出于節(jié)能原因使用包容性緩存;包容性緩存意味著驅(qū)逐要簡單得多,因為 L1 數(shù)據(jù)不需要移動到 L2 才能被驅(qū)逐(或者在提升到 L1 時從 L2 中刪除)?反過來,緩存一致性是使用 MOESI 協(xié)議來維護(hù)的?
L2 緩存本身以全核心頻率運行?而 L1/L2 緩存操作則是全 64 字節(jié)操作,這相當(dāng)于緩存和 CPU 核心之間每秒數(shù)百 GB 的帶寬?雖然 L2 緩存主要用于服務(wù)其自己的直接連接的 CPU 核心,但高通還實施了優(yōu)化的集群到集群監(jiān)聽操作,以應(yīng)對一個集群需要讀取另一個集群的情況?
有趣的是,Snapdragon X 的 4 核集群配置甚至還沒有 Oryon CPU 集群那么大?據(jù)高通工程師稱,該集群設(shè)計實際上具備處理 8 核設(shè)計的所有功能和帶寬,毫無疑問,這讓人回想起其作為服務(wù)器處理器的根源?對于消費級處理器,多個較小的集群為電源管理提供了更高的粒度,并可以作為制造低端芯片(例如 Snapdragon 移動 SoC)的更好的基本構(gòu)建塊,但當(dāng)這些核心位于不同的集群中時(因此必須通過總線接口單元連接到另一個核心),這將帶來一些權(quán)衡,即核心到核心的通信速度會更慢?這是一個很小但值得注意的區(qū)別,因為英特爾和 AMD 的當(dāng)前設(shè)計都在同一個集群/CCX/環(huán)內(nèi)放置了 6 到 8 個 CPU 核心?

深入研究單個 Oryon CPU 內(nèi)核,我們很快就明白了高通為何采用共享 L2 緩存:單個內(nèi)核中的 L1 指令緩存已經(jīng)非常龐大?Oryon 配備 192KB L1 I-Cache,是 Redwood Cove(Meteor Lake)L1 I-Cache 的三倍,甚至比 Zen 4 的還要大?總體而言,6 路關(guān)聯(lián)緩存允許 Oryon 將大量指令保存在 CPU 執(zhí)行單元的本地?但不幸的是,我們手頭沒有 L1I 延遲,無法查看它與其他芯片的比較情況?
總而言之,Oryon 的 fetch/L1 單元每個周期最多可以檢索 16 條指令?
這反過來又為非常寬的解碼前端提供了支持?Oryon 可以在一個時鐘周期內(nèi)解碼多達(dá) 8 條指令,解碼前端比 Redwood Cove (6) 和 Zen 4 (4) 還要寬?而且所有解碼器都是相同的(對稱的),因此無需特殊情況/場景即可實現(xiàn)全吞吐量?
與其他當(dāng)代處理器一樣,這些解碼后的指令以微操作 (uOps) 的形式發(fā)出,以供 CPU 核心進(jìn)一步處理?從技術(shù)上講,每條 Arm 指令最多可以解碼 7 個 uOps,但據(jù)高通稱,Arm v8 的指令與解碼后的微操作的比例通常更接近 1:1?
分支預(yù)測是 CPU 核心性能的另一個主要驅(qū)動因素,這也是 Oryon 毫不吝嗇的另一個領(lǐng)域?Oryon 具有所有常見的預(yù)測器:直接?條件和間接?直接預(yù)測器是單周期的;同時,分支預(yù)測錯誤會帶來 13 個周期的延遲損失?不幸的是,高通并沒有透露分支目標(biāo)緩沖區(qū)本身的大小,所以我們不知道它們到底有多大?
不過,我們確實知道 L1 轉(zhuǎn)換后備緩沖區(qū) (TLB) 的大小,它用于虛擬到物理內(nèi)存地址映射?該緩沖區(qū)可容納 256 個條目,支持 4K 和 64KB 頁面?

翻到 Oryon 的執(zhí)行后端,有很多值得討論的地方?部分原因是這里有很多硬件和很多緩沖區(qū)?Oryon 具有一個相當(dāng)大的 650+ 重排序緩沖區(qū) (ROB),用于通過無序執(zhí)行提取指令并行性和整體性能?這使得高通成為最新的 CPU 設(shè)計師,它拋棄了傳統(tǒng)智慧,推出了一款大型 ROB,避免了聲稱更大的 ROB 帶來的收益遞減?
反過來,指令退出與解碼器塊的最大容量相匹配:8 條指令輸入,8 個 uOps 輸出?如前所述,解碼器在技術(shù)上可以為一條指令發(fā)出多個 uOps,但大多數(shù)情況下它將與指令退出率完美一致?
Oryon 上的寄存器重命名池也相當(dāng)龐大(你感覺到這里有一個共同的主題嗎?)?總共有超過 400 個寄存器可用于整數(shù),另外還有 400 個寄存器可用于饋送矢量單元?
至于實際的執(zhí)行管道本身,Oryon 提供了 6 個整數(shù)管道?4 個 FP/矢量管道和另外 4 個加載/存儲管道?高通沒有提供每個管道的完整映射,因此我們無法介紹所有可能性和特殊情況?但在較高層次上,所有整數(shù)管道都可以執(zhí)行基本的 ALU 操作,而 2 個可以處理分支,2 個可以執(zhí)行復(fù)雜的乘法累加 (MLA) 指令?同時,我們被告知絕大多數(shù)整數(shù)運算具有單周期延遲 - 也就是說,它們在單個周期內(nèi)執(zhí)行?
在浮點/向量方面,每個向量管道都有自己的 NEON 單元?提醒一下,這是一個 Arm v8.7 架構(gòu),因此這里沒有任何向量 SVE 或 Matrix SME 管道;CPU 核心的唯一 SIMD 功能是使用經(jīng)典的 128 位 NEON 指令?這確實將 CPU 限制在比當(dāng)代 PC CPU 更窄的向量上(AVX2 為 256 位寬),但它確實通過所有四個 FP 管道上的 NEON 單元彌補(bǔ)了這一問題?而且,由于我們現(xiàn)在處于 AI 時代,FP/向量單元支持所有常見數(shù)據(jù)類型,一直到 INT8?這里唯一值得注意的遺漏是 BF16,這是 AI 工作負(fù)載的常見數(shù)據(jù)類型;但對于嚴(yán)肅的 AI 工作負(fù)載,這就是 NPU 的用途?

我們在 Oryon 上還看到了數(shù)據(jù)加載/存儲單元?核心的加載/存儲單元非常靈活,這意味著 4 個執(zhí)行管道可以根據(jù)需要在每個周期執(zhí)行任意組合的加載和存儲?加載隊列本身最多可以有 192 個條目,而存儲隊列最多可以有 26 個條目?所有填充都是緩存行的完整大小:64 字節(jié)?
支持加載/存儲單元的 L1 數(shù)據(jù)緩存本身也相當(dāng)大?完全一致的 6 路關(guān)聯(lián)緩存大小為 96KB,是英特爾 Redwood Cove 緩存的兩倍(盡管即將推出的 Lion Cove 將大大改變這一點)?而且它經(jīng)過精心設(shè)計,可以有效支持各種不同的訪問大小?
除此之外,高通的內(nèi)存預(yù)取器有點兒像“秘方”一樣,因為該公司表示,這個相對復(fù)雜的單元對性能的貢獻(xiàn)很大?因此,高通并沒有過多地透露其預(yù)取器的工作原理,但毋庸置疑的是,其準(zhǔn)確預(yù)測和預(yù)取數(shù)據(jù)的能力會對 CPU 核心的整體性能產(chǎn)生巨大影響,尤其是在現(xiàn)代處理器時鐘速度下,DRAM 的行程時間很長?總體而言,高通的預(yù)取算法力求涵蓋多種情況,從簡單的鄰接和跨度到更復(fù)雜的模式,使用過去的訪問歷史來預(yù)測未來的數(shù)據(jù)需求?
相反,Oryon 的內(nèi)存管理單元相對簡單?這是一個功能齊全的現(xiàn)代 MMU,它支持更多深奧的功能,例如嵌套虛擬化 - 允許客戶虛擬機(jī)托管自己的客戶虛擬機(jī)管理程序,以便為更遠(yuǎn)的虛擬機(jī)提供服務(wù)?
此處其他值得注意的功能中,硬件表遍歷器是另一個值得特別提及的功能?如果緩存行不在 L1 或 L2 緩存中,該單元負(fù)責(zé)將緩存行移至 DRAM,最多支持 16 次并發(fā)表遍歷?請記住,這是每個核心的,因此完整的 Snapdragon X 芯片一次最多可以進(jìn)行 192 次表遍歷?

最后,除了 CPU 內(nèi)核和 CPU 集群之外,我們還擁有 SoC 的最高級別:共享內(nèi)存子系統(tǒng)?
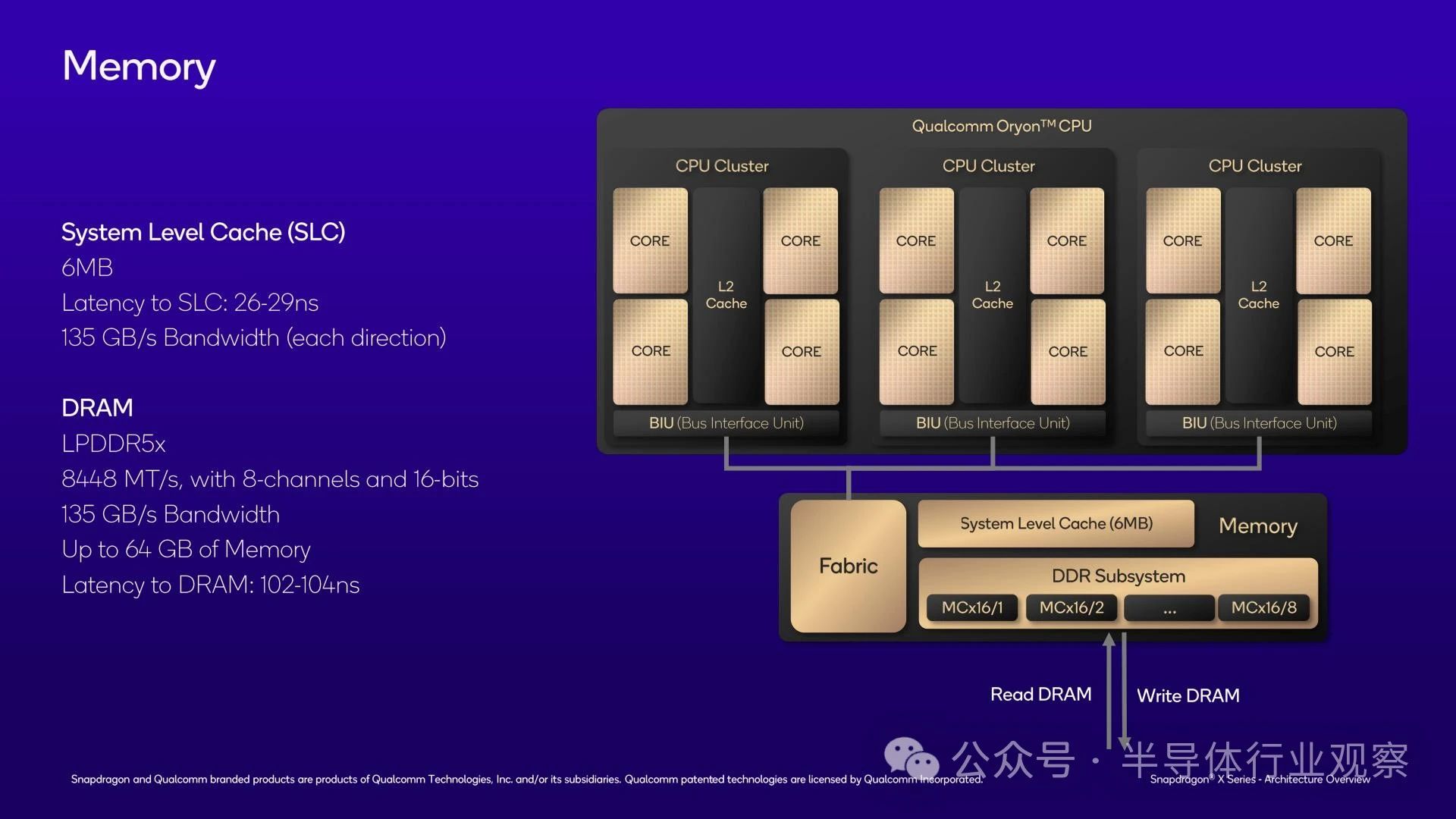
緩存的最后一級就位于此處,與芯片共享 L3 緩存?考慮到芯片的 L1 和 L2 緩存的大小,您可能會認(rèn)為 L3 緩存也相當(dāng)大?但您錯了?事實上,高通只為芯片配備了 6MB 的 L3 緩存,這僅僅是其支持的 36MB L2 緩存的一小部分?
由于該芯片在 L1/L2 級別已經(jīng)具有大量緩存,并且這些緩存之間緊密集成,因此高通在此使用相對較小的犧牲緩存作為進(jìn)入系統(tǒng)內(nèi)存之前的最后一站?與傳統(tǒng)的 x86 CPU 相比,這是一個相當(dāng)大的變化,盡管這對高通來說非常符合品牌定位,其 Arm 移動 SoC 通常也具有相對較小的 L3 緩存?至少好處是 L3 緩存訪問速度相當(dāng)快,延遲僅為 26-29 納秒?并且它具有與 DRAM 相同的帶寬(135GB/秒),可以在其下方的 L2 緩存和其上方的 DRAM 之間傳遞數(shù)據(jù)?
至于內(nèi)存支持,如之前的披露所述,驍龍 X 具有 128 位內(nèi)存總線,支持 LPDDR5X-8448,最大內(nèi)存帶寬為 135GB/秒?在目前的 LPDDR5X 容量下,驍龍 X 最多可以處理 64GB 的 RAM,不過,如果高通在更高密度的 LPDDR5X 芯片開始出貨后確認(rèn)其支持 128GB,我也不會感到太驚訝?
值得注意的是,與其他一些專注于移動領(lǐng)域的芯片不同,驍龍 X 不使用任何類型的封裝內(nèi)存?因此,LPDDR5X 芯片將安裝在設(shè)備主板上,設(shè)備供應(yīng)商可以選擇自己的內(nèi)存配置?
利用 LPDDR5X-8448 內(nèi)存,高通告訴我們 DRAM 延遲應(yīng)該略高于 100ns,為 102-104ns?

最后,我們不妨簡要提一下 CPU 安全性?高通支持現(xiàn)代芯片所需的所有安全功能,包括 Arm TrustZone?每個集群的隨機(jī)數(shù)生成器以及指針身份驗證等安全強(qiáng)化功能?
值得注意的是,高通聲稱 Oryon 可以緩解所有已知的旁道攻擊,包括Spectre,這種攻擊被稱為“不斷給予的禮物”?這個說法很有趣,因為 Spectre 本身并不是硬件漏洞,而是推測執(zhí)行的固有后果?這反過來也是它很難完全防御的原因(最好的防御是讓敏感操作自己隔離)?盡管如此,高通認(rèn)為,通過在硬件中實施各種混淆工具,他們可以防范這類旁道攻擊?所以看看這將如何發(fā)展將會很有趣?
關(guān)于 x86 仿真的說明
最后,我想花點時間簡單介紹一下有關(guān) Oryon 上的 x86 仿真的信息?
高通的 x86 仿真方案比我們在 Apple 設(shè)備上習(xí)慣的方案要復(fù)雜得多,因為在 Windows 世界中,沒有一家供應(yīng)商能夠同時控制硬件和軟件堆棧?因此,盡管高通可以談?wù)撍麄兊挠布?但他們無法控制軟件方面的問題 - 而且他們不會冒著集體失言的風(fēng)險代替微軟發(fā)言?因此,Snapdragon X 設(shè)備上的 x86 仿真本質(zhì)上是兩家公司的聯(lián)合項目,高通提供硬件,微軟提供 Prism 轉(zhuǎn)換層?
但是,雖然 x86 模擬在很大程度上是一項軟件任務(wù)(Prism 承擔(dān)了大部分繁重的工作),但 Arm CPU 供應(yīng)商仍然可以進(jìn)行某些硬件調(diào)整來提高 x86 性能?而高通則已經(jīng)做出了這些調(diào)整?Oryon CPU 內(nèi)核具有硬件輔助功能,可以提高 x86 浮點性能?為了解決這個可以說是房間里的大象問題,Oryon 還為 x86 獨特的內(nèi)存存儲架構(gòu)提供了硬件調(diào)整——這被廣泛認(rèn)為是蘋果在自己的芯片上實現(xiàn)高 x86 模擬性能的關(guān)鍵進(jìn)步之一?
不過,沒有人會以為高通的芯片能夠像原生芯片一樣快速運行 x86 代碼?仍然會有一些轉(zhuǎn)換開銷(具體多少取決于工作量),性能關(guān)鍵型應(yīng)用程序仍將受益于原生編譯為 AArch64?但高通在這方面并不完全受微軟的擺布,他們已經(jīng)做出了硬件調(diào)整來提高其 x86 仿真性能?
在兼容性方面,預(yù)計這里最大的障礙是 AVX2 支持?與 Oryon 上的 NEON 單元相比,x86 矢量指令集更寬(256b 對 128b),而且指令本身并不完全重疊?正如高通所說,AVX 到 NEON 的轉(zhuǎn)換是一項艱巨的任務(wù)?不過,我們知道這是可以做到的——蘋果本周悄悄地將 AVX2 支持添加到他們的游戲移植工具包 2中——因此,看看未來幾代 Oryon CPU 核心會發(fā)生什么將會很有趣?與蘋果的生態(tài)系統(tǒng)不同,x86 不會在 Windows 生態(tài)系統(tǒng)中消失,因此轉(zhuǎn)換 AVX2(最終是 AVX-512 和AVX10 !)的需求也永遠(yuǎn)不會消失?
Adreno X1 GPU 架構(gòu):更熟悉的面孔
接下來,我們來談?wù)勻旪?X SoC 的 GPU 架構(gòu):Adreno X?
與 Oryon CPU 內(nèi)核不同,Adreno X1 并非全新的硬件架構(gòu)?事實上,在它之前已經(jīng)推出了三代 8cx SoC,它甚至對 Windows 來說都不算新東西?不過,高通多年來一直對其 GPU 架構(gòu)守口如瓶,因此 GPU 架構(gòu)對 AnandTech 讀者來說可能也是新東西?可以這么說,十多年來,我一直在試圖從高通那里獲得詳細(xì)的披露信息,而隨著驍龍 X 的推出,他們終于實現(xiàn)了這一目標(biāo)?
從高層次來看,Adreno X1 GPU 架構(gòu)是高通目前正在研發(fā)的 Adreno 架構(gòu)系列的最新版本,其中 X1 代表第 7代?Adreno 本身基于 15 年前從 ATI 收購而來(Adreno 是 Radeon 的字母變位詞),多年來,高通的 Adreno 架構(gòu)一直是 Android 領(lǐng)域最強(qiáng)的 GPU?
當(dāng)然,Windows 領(lǐng)域的情況略有不同,因為獨立 GPU 將集成 GPU 推到了一邊,無法處理絕對需要高 GPU 性能的工作負(fù)載?而且由于游戲開發(fā)從未完全脫離 GPU 架構(gòu)/驅(qū)動程序,高通多年來在 Windows 市場的微不足道的存在導(dǎo)致他們經(jīng)常被游戲開發(fā)商忽視?不過,高通并不是 Windows 游戲的新手,這讓他們在試圖占據(jù)更大的 Windows 市場份額時占據(jù)了優(yōu)勢?
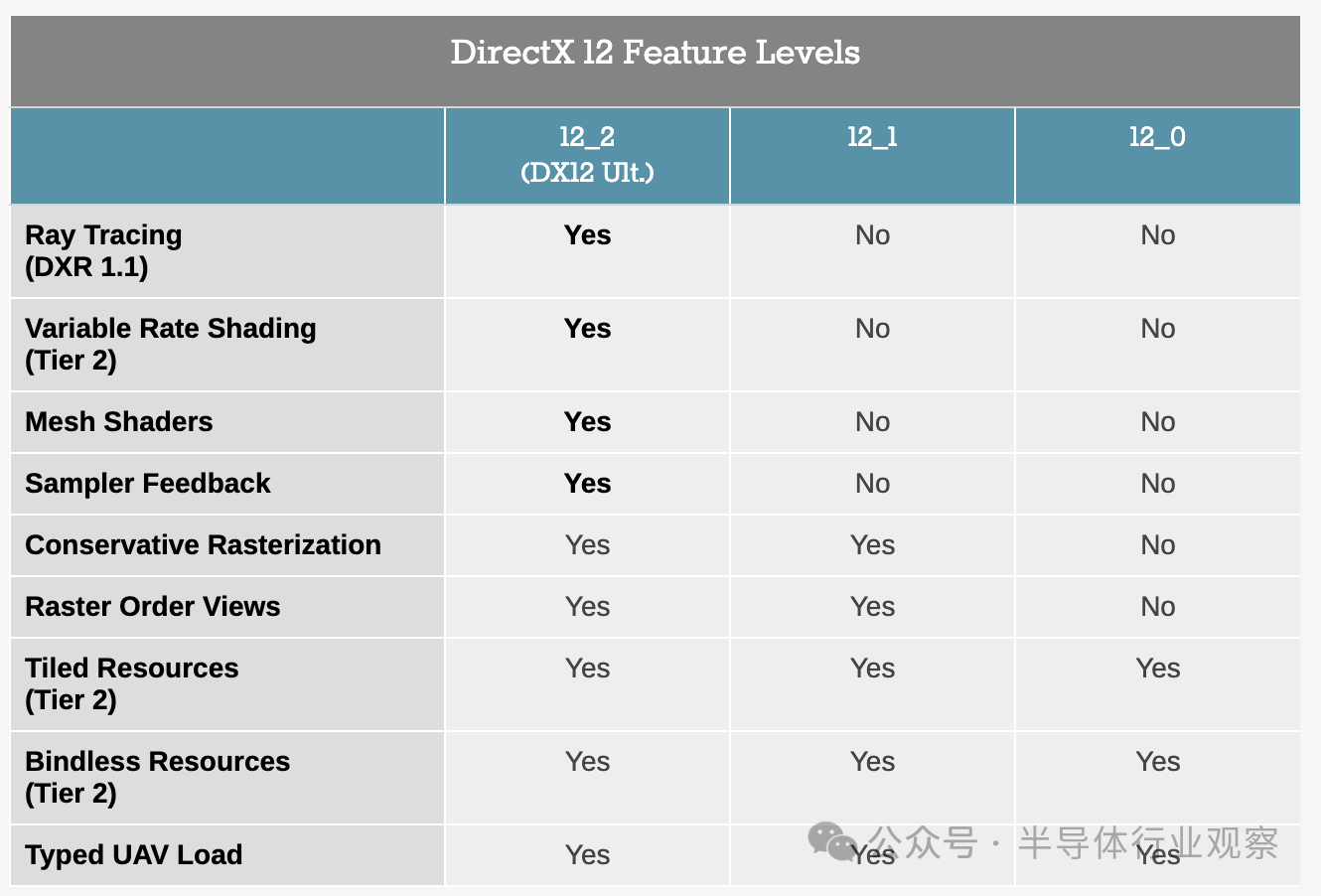
從功能角度來看,與當(dāng)代 x86 SoC 相比,Adreno X1 GPU 架構(gòu)不幸有點過時?雖然該架構(gòu)確實支持光線追蹤,但該芯片無法支持完整的DirectX 12 Ultimate(功能級別 12_2)功能集?這意味著它必須向 DirectX 應(yīng)用程序報告自己為功能級別 12_1 GPU,這意味著大多數(shù)游戲?qū)⑾拗谱约菏褂眠@些功能?
盡管如此,Adreno X1 確實支持一些高級功能,這些功能已經(jīng)在 Android 上積極使用,因為 DirectX 的功能級別并不存在?如前所述,它支持光線追蹤,這通過 Vulkan API 及其光線查詢調(diào)用在 Windows 應(yīng)用程序中公開?考慮到 Vulkan 在 Windows 上的使用有限,高通可以理解地不會深入探討這個主題,但聽起來高通的實現(xiàn)是2 級設(shè)計,具有硬件光線測試,但沒有類似于 AMD 的 RDNA2 的硬件 BVH 處理?

另外,還支持可變速率著色 (VRS) 第 2 層,這對于優(yōu)化移動 GPU 上的著色器工作負(fù)載至關(guān)重要?因此,似乎阻礙 X1 獲得 DirectX 12 Ultimate 支持的功能是網(wǎng)格著色器和采樣器反饋,誠然,這是一些相當(dāng)大的硬件變化?
在 API 支持方面,如前所述,Adreno X1 GPU 支持 DirectX 和 Vulkan?高通為 DirectX 12 和 DirectX 11?Vulkan 1.3 和 OpenCL 3.0 提供原生驅(qū)動程序/路徑?這里唯一值得注意的例外是 DirectX 9 支持,與 SoC 供應(yīng)商英特爾一樣,它是使用D3D9on12實現(xiàn)的,它將 DX9 命令轉(zhuǎn)換為 DX12?如今 DX9 游戲很少見(15 年前 API 就被 DX10/11 取代了),但由于這是 Windows,因此向后兼容性是持續(xù)的期望?
相反,甚至支持微軟用于機(jī)器學(xué)習(xí)的低級 GPU 訪問的新 DirectML API?高通甚至優(yōu)化了為 GPU 編寫的元命令,以便利用 DirectML 的軟件可以更高效地運行,而無需了解架構(gòu)的其他任何信息?
Adreno X1 GPU 架構(gòu)詳解
除了高級功能之外,我們來看看低級架構(gòu)?

Adreno X1 GPU 分為 6 個著色器處理器塊,每個塊提供 256 個 FP32 ALU,總共 1536 個 ALU?峰值時鐘速度為 1.5GHz,這讓驍龍 X 上的集成 GPU 的最大吞吐量達(dá)到 4.6 TFLOPS(低端 SKU 的吞吐量較低)?
與其他 GPU 一樣,GPU 的前端分為傳統(tǒng)的前端/SP/后端設(shè)置,前端負(fù)責(zé)處理三角形設(shè)置和光柵化,以及 GPU 基于圖塊的渲染模式的合并?值得注意的是,GPU 前端每時鐘可以設(shè)置和光柵化 2 個三角形,這在 2024 年的 PC 領(lǐng)域不會引起任何關(guān)注,但對于集成 GPU 來說已經(jīng)很不錯了?為了提高性能,前端還可以進(jìn)行早期深度測試,以拒絕在光柵化之前永遠(yuǎn)不會可見的多邊形?
同時,后端由 6 個渲染輸出單元 (ROP) 組成,每個單元每個周期可以處理 8 個像素,總共渲染 48 個像素/時鐘?渲染后端插入本地緩存,以及高通稱為 GMEM 的重要暫存器內(nèi)存?
單個著色器處理器塊本身是比較常見的,特別是如果你看過 NVIDIA GPU 架構(gòu)圖的話?每個 SP 進(jìn)一步細(xì)分為兩個微管道(微著色器管道紋理管道,或 uSPTP),由其自己的專用調(diào)度程序和其他資源(如本地內(nèi)存?加載/存儲單元和紋理單元)控制?
每個 uSPTP 提供 128 個 FP32 ALU?而且,有點令人驚訝的是,還有一組單獨的 256 個 FP16 ALU,這意味著 Adreno X1 在處理 FP16 和 FP32 數(shù)據(jù)時不必共享資源,這與在 FP32 ALU 上執(zhí)行 FP16 操作的架構(gòu)不同?不過,如果 GPU 調(diào)度程序確定需要,FP32 單元也可以用于 FP16 操作?
最后,有 16 個基本函數(shù)單元 (EFU),用于處理超越函數(shù),例如 LOG?SQRT 和其他罕見但重要的數(shù)學(xué)函數(shù)?
令人驚訝的是,Adreno X1 使用的波前尺寸相當(dāng)大?根據(jù)模式,高通使用 64 或 128 通道寬的波前,高通告訴我們,他們通常使用 128 寬的波前進(jìn)行 16 位操作(例如片段著色器),而 64 寬的波前用于 32 位操作(例如像素著色器)?
相比之下,AMD 的 RDNA 架構(gòu)使用 32/64 寬波前,而 NVIDIA 的波前/扭曲始終為 32 寬?寬設(shè)計在 PC 領(lǐng)域已經(jīng)失寵,因為難以保持饋電(發(fā)散太大),所以這很有趣?盡管人們通常擔(dān)心波前大小,但考慮到高通智能手機(jī) SoC 的高 GPU 性能,它似乎對高通來說效果很好——考慮到手機(jī)屏幕的高分辨率,這絕非易事?
除了 ALU 之外,每個 uSPTP 都包含自己的紋理單元,每個 uSPTP 每時鐘能夠輸出 8 個紋理像素?這里還有有限的圖像處理功能,包括紋理過濾,甚至用于生成運動矢量的 SAD/SAS 指令?
最后,每個 uSPTP 中都有相當(dāng)多的寄存器空間?除了 L1 紋理緩存外,還有總共 192KB 的通用寄存器,用于為各個塊提供信息并試圖隱藏波前的延遲氣泡?

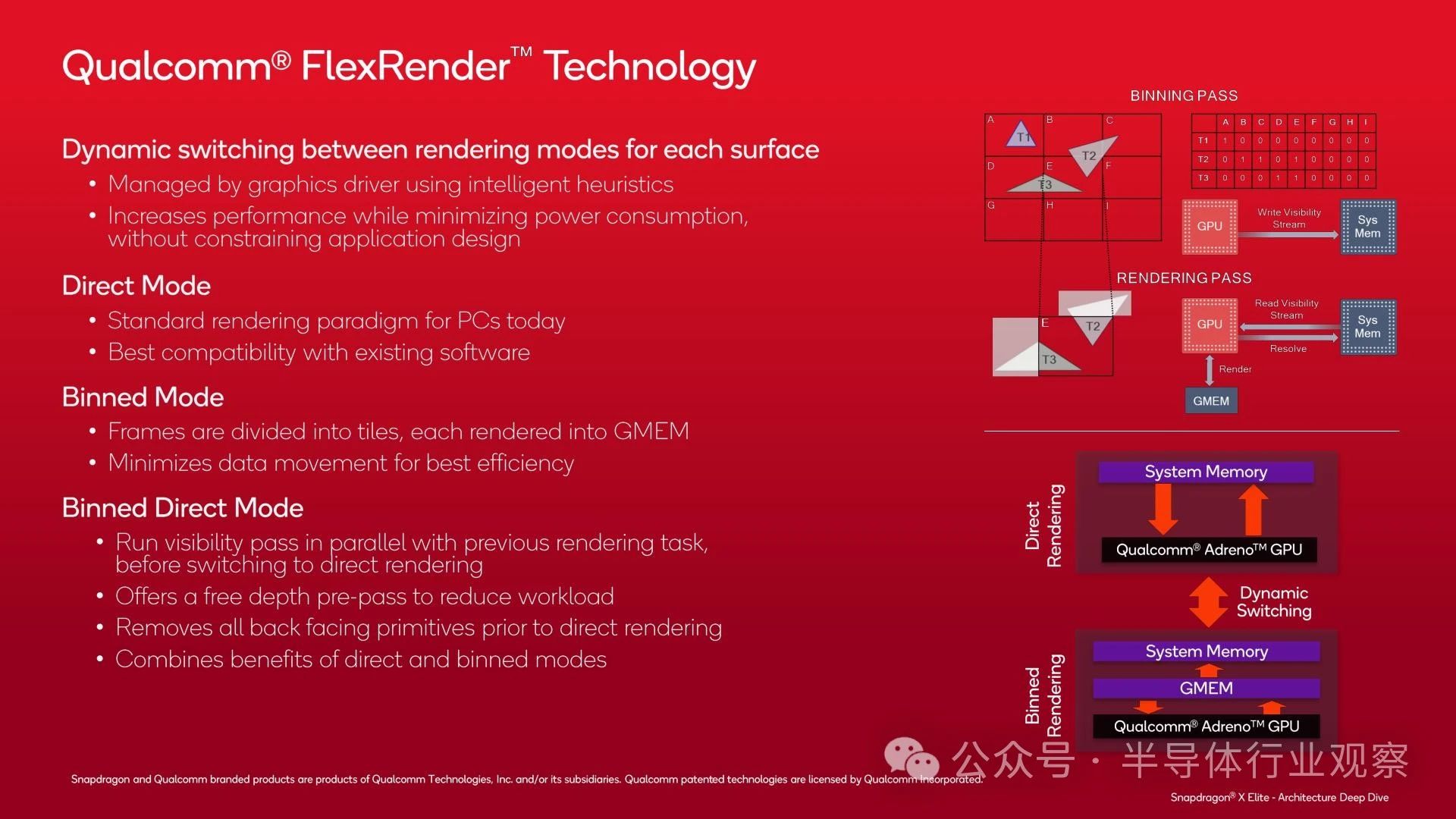
如前所述,Adreno X1 支持多種渲染模式,以獲得最佳性能,該公司稱之為 FlexRender 技術(shù)?這是一個在 PC GPU 設(shè)計中不太常見的主題,但由于歷史和效率原因,在移動領(lǐng)域卻更為重要?
除了傳統(tǒng)的直接/即時模式渲染方法(大多數(shù) PC GPU 的典型模式)之外,高通還支持基于圖塊的渲染,他們稱之為合并模式?與其他基于圖塊的渲染器一樣,合并模式將屏幕分成多個圖塊,然后分別渲染每個圖塊?這允許 GPU 一次只處理一部分?jǐn)?shù)據(jù),將大部分?jǐn)?shù)據(jù)保存在其本地緩存中,并最大限度地減少流向 DRAM 的流量,這既耗電又會限制性能?
最后,Adreno X1 有第三種模式,它結(jié)合了分箱渲染和直接渲染的優(yōu)點,他們稱之為分箱直接模式?此模式在切換到直接渲染之前運行分箱可見性通道,作為進(jìn)一步剔除背面(不可見)三角形的手段,以便它們不會被光柵化?只有在剔除這些數(shù)據(jù)后,GPU 才會切換到直接渲染模式,現(xiàn)在工作量減少了?
使分級渲染模式正常運行的關(guān)鍵是 GPU 的 GMEM,這是一個 3MB 的 SRAM 塊,可作為 GPU 的高帶寬暫存器?從架構(gòu)上講,GMEM 不僅僅是一個緩存,因為它與系統(tǒng)內(nèi)存層次結(jié)構(gòu)分離,并且 GPU 幾乎可以對內(nèi)存執(zhí)行任何操作(包括在必要時將其用作緩存)?
GMEM 塊的大小為 3MB,整體上不算很大?但足以存儲一個圖塊,從而防止大量流量沖擊系統(tǒng)內(nèi)存?而且它的速度也很快,帶寬為 2.3TB/秒,足以讓 ROP 全速運行,而不受內(nèi)存帶寬的限制?
有了 GMEM 塊,在理想情況下,GPU 只需要在完成渲染該圖塊時,每部作品向 DRAM 寫入一次數(shù)據(jù)?當(dāng)然,在實踐中,DRAM 流量會比這更多,但這是高通避免 GPU 向 DRAM 寫入數(shù)據(jù)而占用內(nèi)存帶寬和電量的關(guān)鍵功能之一?
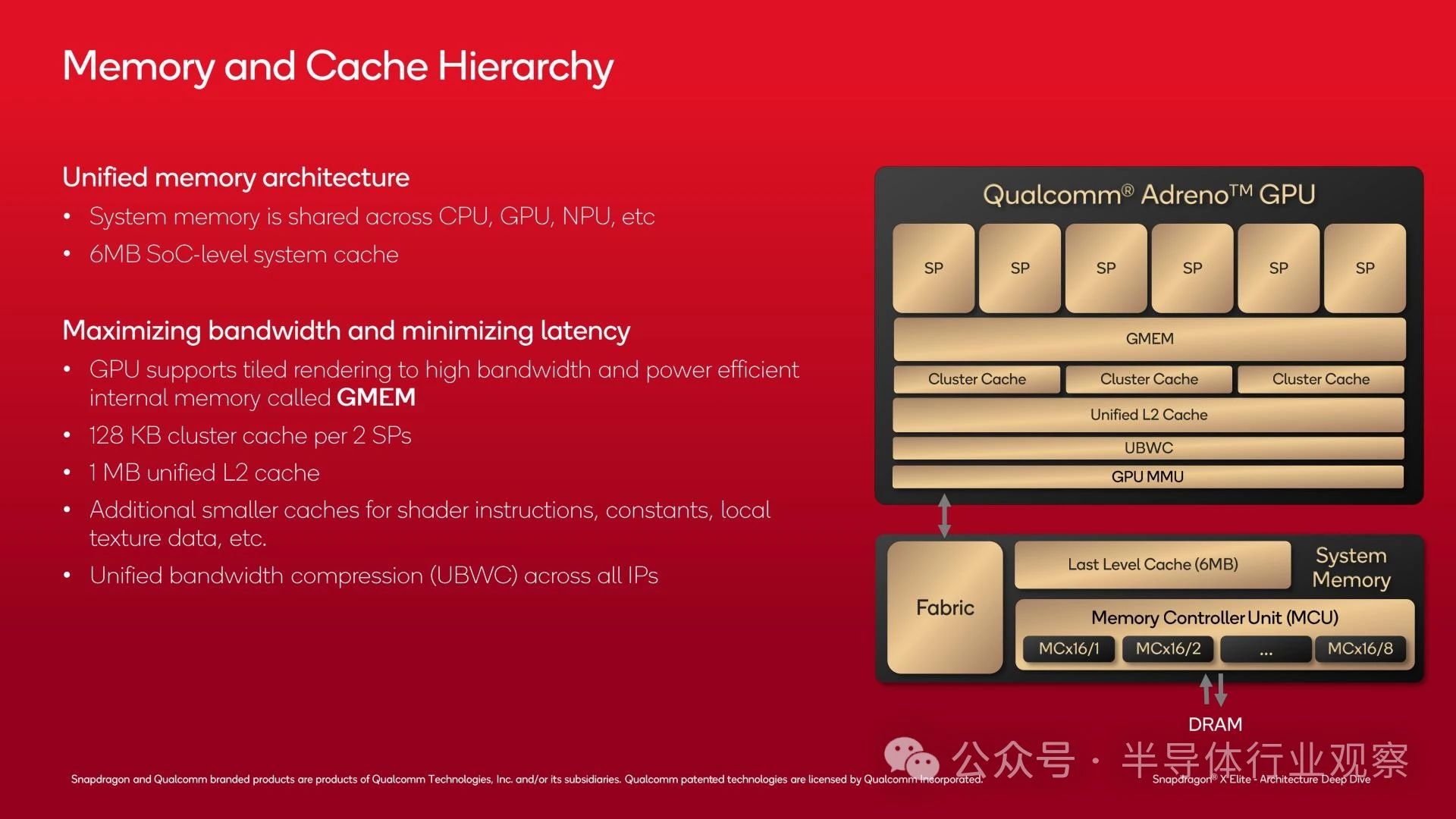
當(dāng)Adreno X1 確實需要進(jìn)入系統(tǒng)內(nèi)存時,它會經(jīng)過自己剩余的緩存,最后到達(dá) Snapdragon X 的共享內(nèi)存控制器?
在 GMEM 之上,每對 SP 都有一個 128KB 的集群緩存(對于完整的 Snapdragon X,總共有 384KB)?而在此之上,還有一個 1MB 的 GPU 統(tǒng)一 L2 緩存?
最后,剩下系統(tǒng)級緩存 (L3/SLC),它為 GPU 上的所有處理塊提供服務(wù)?當(dāng)所有其他方法都失敗時,還有 DRAM?
最后,值得注意的是,Adreno X1 GPU 還在 GPU 內(nèi)包含一個專用的 RISC 控制器,用作 GPU 管理單元 (GMU)?GMU 提供多種功能,其中最重要的是 GPU 內(nèi)的電源管理?GMU 與 SoC 其他地方的電源管理請求協(xié)同工作,允許芯片根據(jù) SoC 決定的最佳性能分配方法在不同的塊之間重新分配功率?
性能和初步想法
最后,在結(jié)束這次架構(gòu)深度剖析之前,讓我們先來看看高通的幾張性能幻燈片?雖然全世界下周零售設(shè)備發(fā)布時就能親眼看到驍龍 X 的性能,但在此之前,它讓我們對預(yù)期結(jié)果有了更多的了解?但一定要謹(jǐn)慎對待?
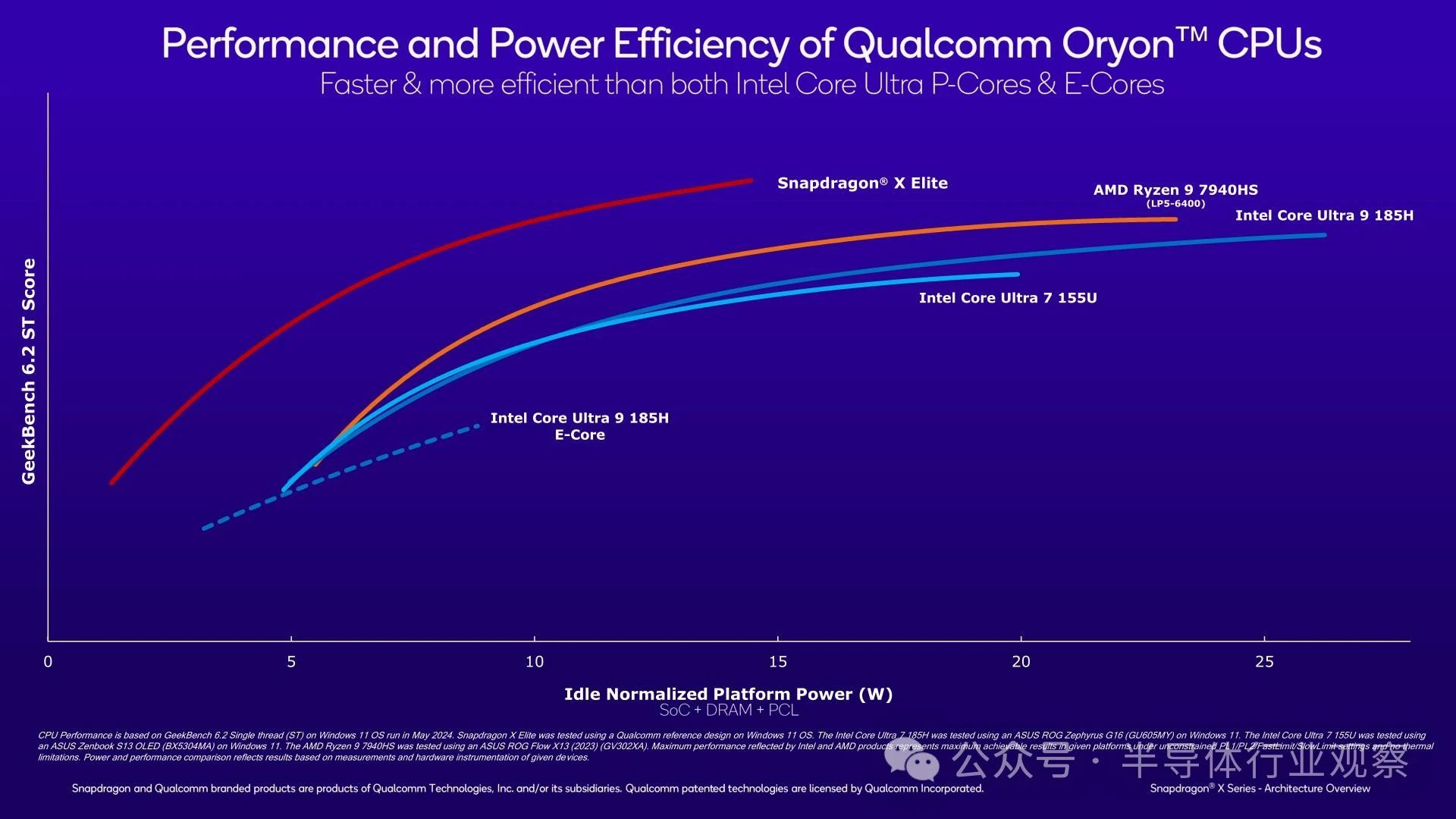
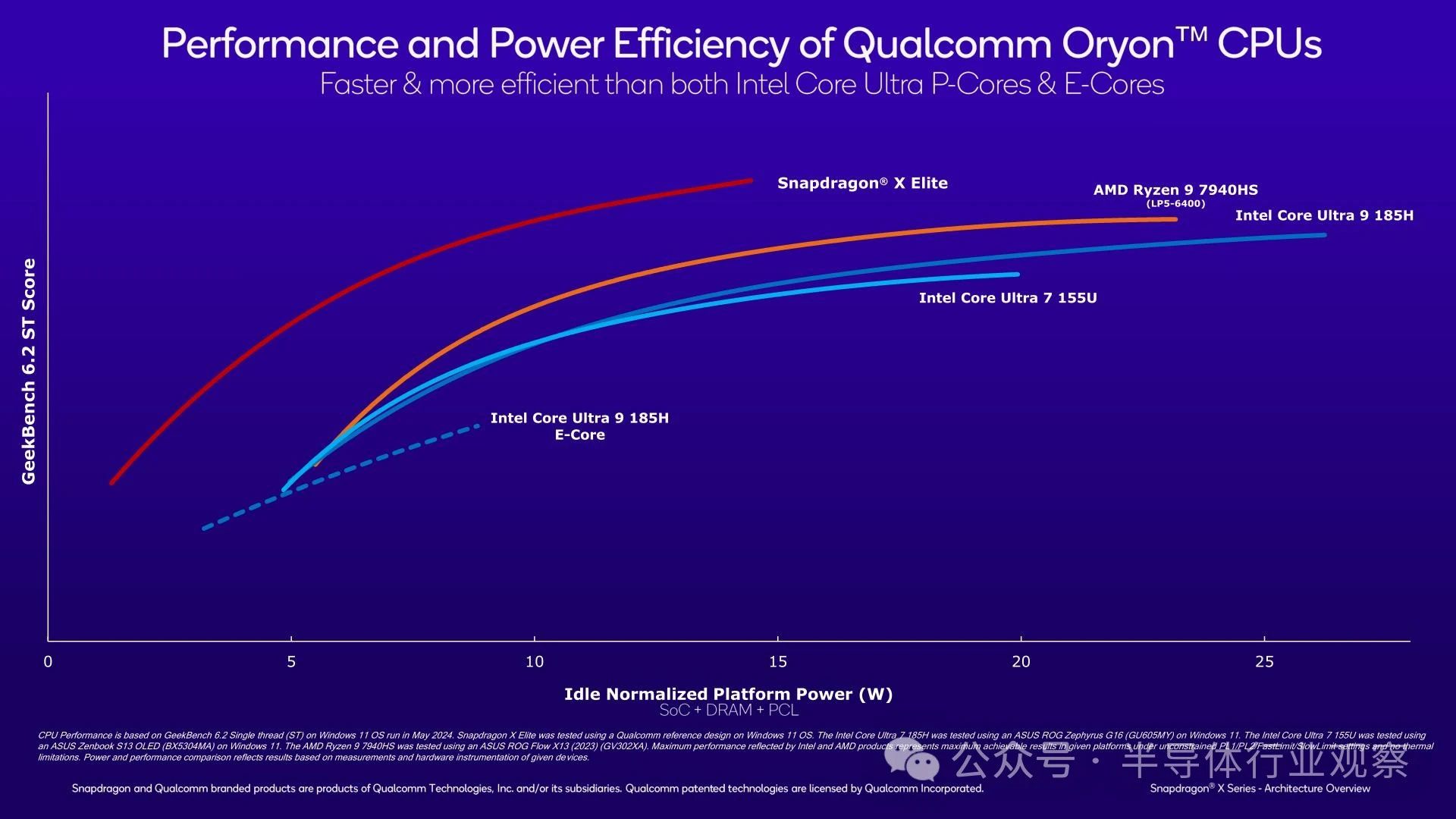
在 CPU 方面,高通聲稱 Snapdragon X Elite 可以在 GeekBench 6.2 單線程測試中擊敗所有當(dāng)代 PC 競爭對手?而且,在考慮能效時,其領(lǐng)先優(yōu)勢也相當(dāng)顯著?
簡而言之,高通聲稱,即使 x86 核心的 TDP 不受限制,Snapdragon X Elite 中的 Oryon CPU 核心在絕對性能方面也能擊敗 Redwood Cove(Meteor Lake)和 Zen 4(Phoenix)?鑒于移動 x86 芯片的加速高達(dá) 5GHz,這是一個大膽的說法,但并非不可能?
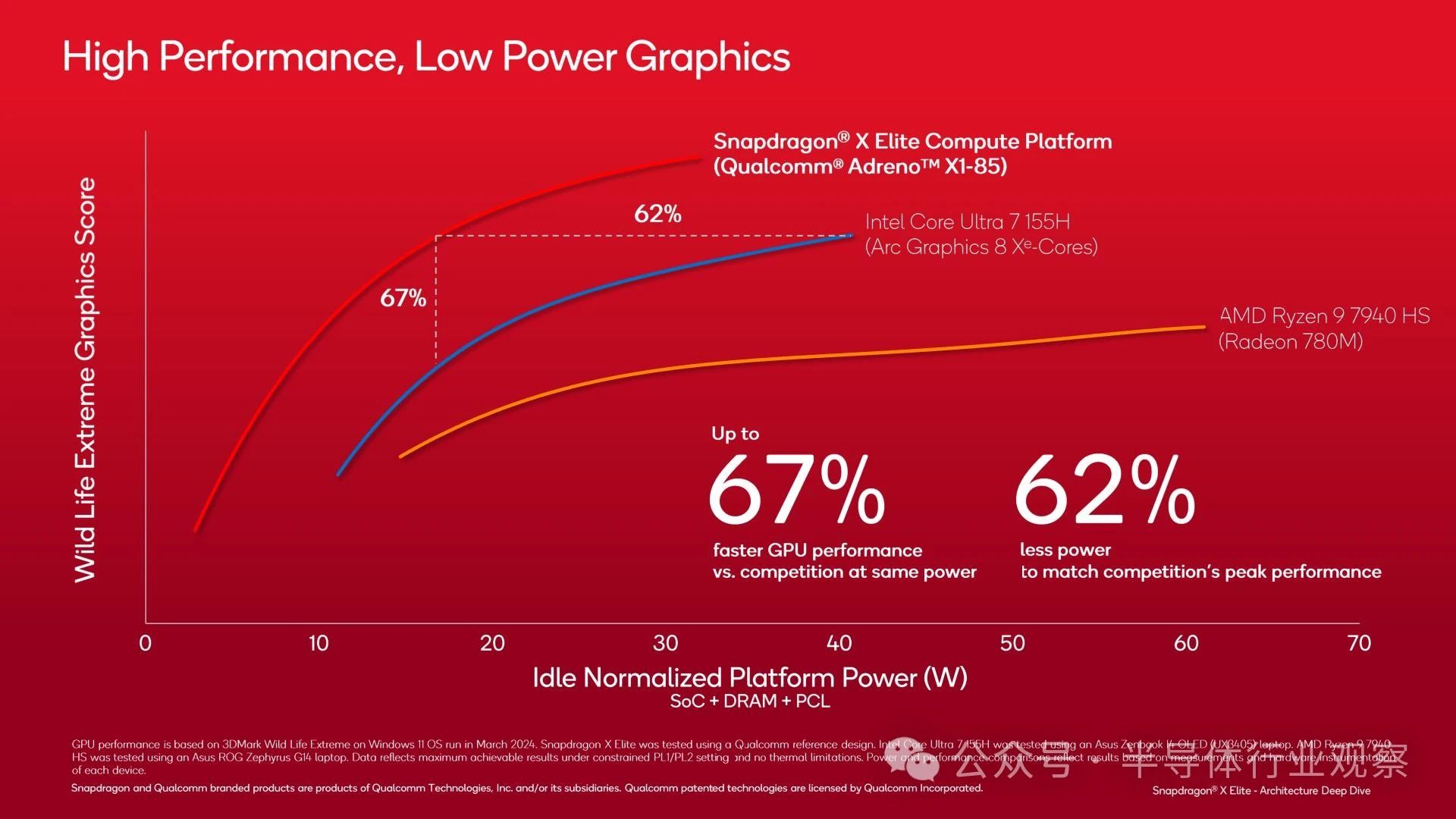
與此同時,在 GPU 方面,高通也取得了類似的能效提升?不過,所討論的工作負(fù)載 3DMark WildLife Extreme 不太可能轉(zhuǎn)化為大多數(shù)游戲,因為這是一個專注于移動設(shè)備的基準(zhǔn)測試,長期以來一直在每個移動 SoC 供應(yīng)商的驅(qū)動程序中經(jīng)過反復(fù)優(yōu)化?
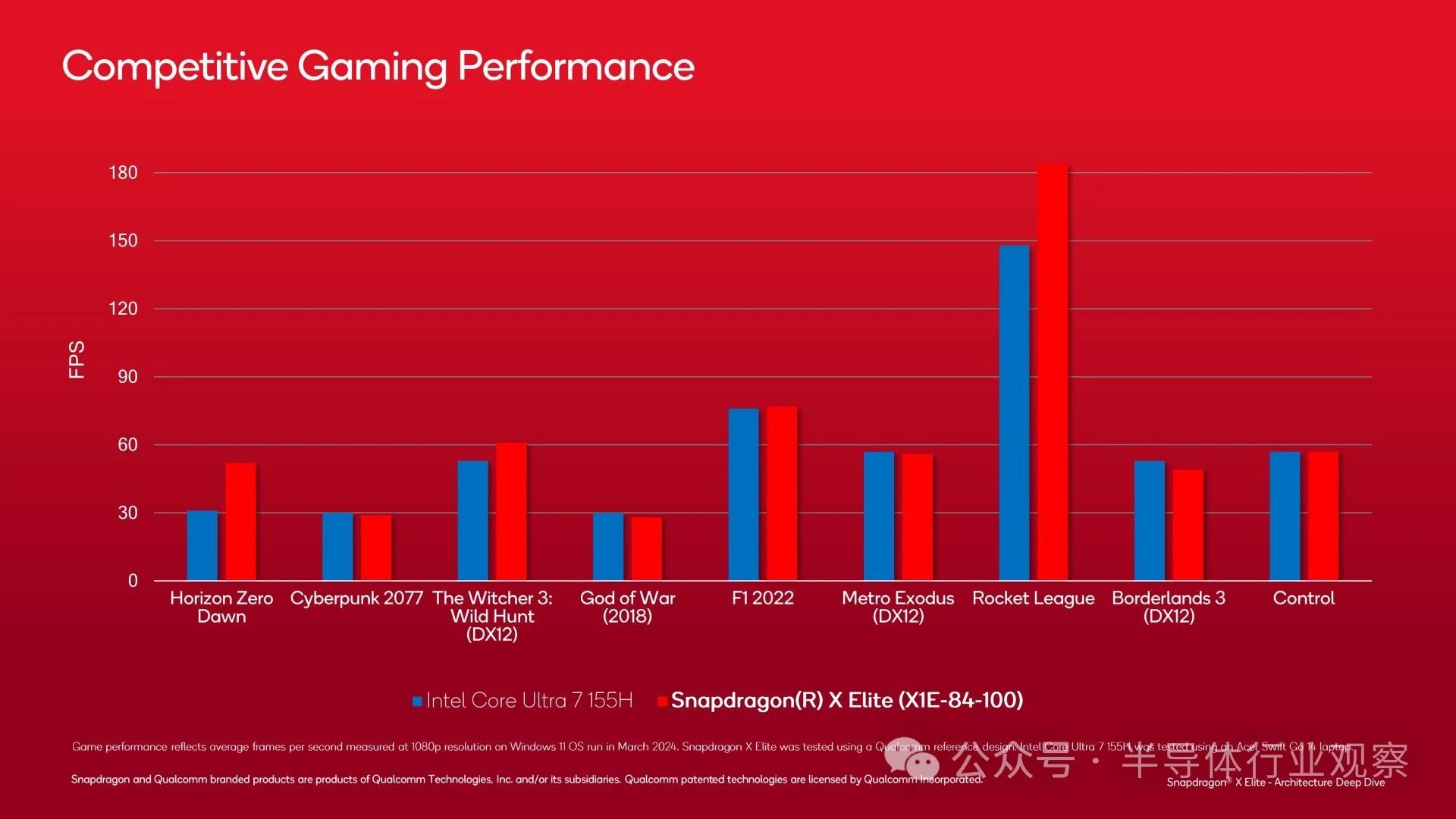
使用實際游戲進(jìn)行的性能基準(zhǔn)測試在這里可能更有用?盡管高通可能在挑選一些好產(chǎn)品,但頂級驍龍 X SKU 經(jīng)常與英特爾的 Core Ultra 7 155H 交鋒?不可否認(rèn)的是,它的整體表現(xiàn)并不令人印象深刻,但很高興看到高通目前在真實游戲中的表現(xiàn)?在這種情況下,即使只是英特爾更好的移動芯片之一的平局/擊敗,也不算糟糕?
初步想法
以上就是我們對高通驍龍 X SoC 架構(gòu)的首次深入研究?高通將長期投資 Windows-on-Arm 生態(tài)系統(tǒng),希望這將成為眾多生態(tài)系統(tǒng)中的第一個,因為該公司正在尋求成為第三大 Windows CPU/SoC 供應(yīng)商?
但 Snapdragon X SoC 及其 Oryon CPU 核心的最終意義不僅僅在于作為筆記本電腦的 SoC?即使高通在這方面取得了巨大成功,他們出貨的 PC 芯片數(shù)量與他們真正的實力基礎(chǔ):Android SoC 領(lǐng)域相比也只是九牛一毛?而 Oryon 將在這里照亮高通移動 SoC 實現(xiàn)重大變革的道路?
正如高通自 Oryon 之旅開始以來所指出的那樣,這最終將成為高通所有產(chǎn)品的核心 CPU 內(nèi)核?從本月開始的 PC SoC 最終將擴(kuò)展到包括驍龍 8 系列等移動 SoC,再往前走,還將是高通的汽車產(chǎn)品和 XR 耳機(jī) SoC 等高端分支?雖然我懷疑我們是否真的會從上到下地在高通的產(chǎn)品中看到 Oryon 及其繼任者(該公司需要小而便宜的 CPU 內(nèi)核來支持其預(yù)算產(chǎn)品線,如驍龍 6 和驍龍 4),但毫無疑問,從長遠(yuǎn)來看,它將成為他們大多數(shù)產(chǎn)品的基石?這就是制造自己的 CPU 內(nèi)核的差異化價值——通過在盡可能多的地方使用它來從 CPU 內(nèi)核中獲得最大價值?
最終,高通在過去 8 個月中一直在大肆宣傳其下一代 PC SoC 及其定制的 CPU 核心,現(xiàn)在是時候讓所有部件都到位了?在 PC CPU 領(lǐng)域擁有第三個競爭對手(并且是基于 Arm 的競爭對手)的前景令人興奮,但幻燈片和廣告不是硬件和基準(zhǔn)?因此,我們熱切地等待下周會帶來什么,看看高通的工程實力是否能夠?qū)崿F(xiàn)公司的宏偉抱負(fù)?


