當(dāng)談到人工智能系統(tǒng)時,我們已經(jīng)很少看到這樣的東西:加速器和將一堆加速器粘合在一起形成一個共享計算綜合體的基礎(chǔ)主板的標(biāo)價?
但在最近于臺灣臺北舉行的 Computex IT 會議上,急于在 AI 訓(xùn)練和推理方面大展身手的英特爾做了一件 Nvidia 和 AMD 都沒有做過的事情:為其當(dāng)前和前幾代 AI 加速器提供定價?我們預(yù)計 Nvidia?AMD 或任何其他 AI 加速器和系統(tǒng)初創(chuàng)公司不會很快效仿,所以不要太興奮?
但是,Gaudi 2 和 Gaudi 3 加速器的定價以及一些基準(zhǔn)測試結(jié)果以及這些機(jī)器的峰值進(jìn)給和速度的披露,讓我們有機(jī)會進(jìn)行一些競爭分析?
英特爾談?wù)撈涠▋r的原因很簡單?該公司正試圖出售一些人工智能芯片,以彌補(bǔ)其未來“Falcon Shores” GPU 在 2025 年底投入使用以及后續(xù)“Falcon Shores 2” GPU 在 2026 年上市的成本,為此它必須展示出良好的性價比以及具有競爭力的性能?
這一點尤為重要,因為 Gaudi 3 芯片于 4 月開始出貨,是英特爾于 2019 年 12 月以 20 億美元收購 Habana Labs 后獲得的 Gaudi 加速器系列的終結(jié)者?
由于“Ponte Vecchio”Max 系列 GPU 的發(fā)熱量和制造成本極高(這些 GPU 是阿貢國家實驗室“Aurora”超級計算機(jī)的核心,已被安裝到其他幾臺機(jī)器中,并且在完成這些交易后幾乎立即被封存),英特爾正試圖彌補(bǔ)延遲已久的 Ponte Vecchio 和有望于明年年底準(zhǔn)時推出的 Falcon Shores 之間的差距?
正如英特爾在 2023 年 6 月透露的那樣,Falcon Shores 芯片將采用 Gaudi 系列的大規(guī)模并行以太網(wǎng)結(jié)構(gòu)和矩陣數(shù)學(xué)單元,并將其與為 Ponte Vecchio 創(chuàng)建的 Xe GPU 引擎合并?這樣,Falcon Shores 可以同時進(jìn)行 64 位浮點處理和矩陣數(shù)學(xué)處理?Ponte Vecchio 沒有矩陣處理,只有矢量處理,這是為了滿足 Argonne 的 FP64 需求而故意為之?這很好,但這意味著 Ponte Vecchio 不一定適合 AI 工作負(fù)載,這會限制它的吸引力?因此,Gaudi 和 X e計算單元合并為單個 Falcon Shores 引擎?
我們對 Falcon Shores 了解不多,但我們知道它的重量為 1,500 瓦,比預(yù)計明年初批量出貨的頂級“Blackwell” B200 GPU的功耗和散熱量高出 25% ,后者的額定功率為 1,200 瓦,以 FP4 精度提供 20 petaflops 的計算能力?在耗電量多 25% 的情況下,Falcon Shores 的性能最好在相同浮點精度水平和大致相同的芯片制造工藝水平下比 Blackwell 至少高 25%?更好的是,英特爾最好使用其預(yù)計在 2025 年投入生產(chǎn)的英特爾 18A 制造工藝來制造 Falcon Shores,并且它的浮點性能最好比這更強(qiáng)?而 Falcon Shores 2 最好采用更小的英特爾 14A 工藝,預(yù)計在 2026 年投入生產(chǎn)?
英特爾早就該停止在代工和芯片設(shè)計業(yè)務(wù)上浪費時間了?臺積電的創(chuàng)新步伐無情,而英偉達(dá)的 GPU 路線圖也毫不松懈?2025 年的“Blackwell Ultra”將帶來 HBM 內(nèi)存升級,GPU 計算能力也可能提升,“Rubin”GPU 將于 2026 年推出,而“Rubin Ultra”后續(xù)產(chǎn)品將于 2027 年推出?
與此同時,英特爾去年 10 月表示,其 Gaudi 加速器銷售渠道價值 20 億美元,并在今年 4 月補(bǔ)充稱,預(yù)計 2024 年 Gaudi 加速器的銷售額將達(dá)到 5 億美元?這與AMD 今年預(yù)計的 40 億美元 GPU 銷售額(我們認(rèn)為這個數(shù)字太低,更有可能是 50 億美元)或 Nvidia 今年在數(shù)據(jù)中心計算領(lǐng)域可能獲得的 1000 億美元或更多收入(僅數(shù)據(jù)中心 GPU,沒有網(wǎng)絡(luò),沒有 DPU)相比微不足道?但清理 20 億美元的渠道意味著要支付 Falcon Shores 和 Falcon Shores 2 的費用,因此英特爾的積極性很高?
因此,英特爾在其 Computex 簡報會上公布了定價并制定了基準(zhǔn)測試,以展示 Gaudi 3 與當(dāng)前“Hopper”H100 GPU 相比的競爭力?
英特爾首先進(jìn)行的比較是針對 AI 訓(xùn)練,針對的是具有 1750 億個參數(shù)的 GPT-3 大型語言模型和具有 700 億個參數(shù)的 Llama 2 模型:

上述 GPT-3 數(shù)據(jù)基于 MLPerf 基準(zhǔn)測試運行,而 Llama 2 數(shù)據(jù)則基于 Nvidia 發(fā)布的 H100 結(jié)果和英特爾的估計?GPT 基準(zhǔn)測試在具有 8,192 個加速器的集群上運行 - 英特爾 Gaudi 3 具有 128 GB HBM,而 Nvidia H100 具有 80 GB HBM?Llama 2 測試在僅有 64 個設(shè)備的機(jī)器上運行?
為了進(jìn)行推理,英特爾進(jìn)行了兩次比較:一次是在一系列測試中將具有 128 GB HBM 的 Gaudi 3 與具有 80 GB HBM 的 H100 進(jìn)行比較,另一次是將具有同樣 128 GB 內(nèi)存的 Gaudi 3 與具有 141 GB HBM 的 H200 進(jìn)行比較?此處發(fā)布了 Nvidia 數(shù)據(jù),用于在各種模型上使用 TensorRT 推理層的各種模型?英特爾數(shù)據(jù)是針對 Gaudi 3 預(yù)測的?
以下是第一個比較,H100 80 GB 與 Gaudi 3 128 GB:
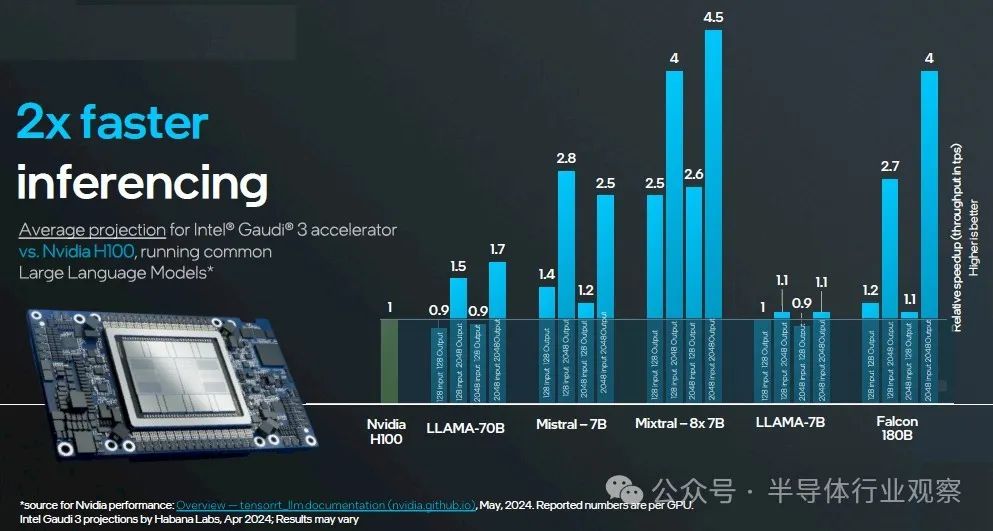
以下是第二次比較,H200 141 GB 與 Gaudi 3 128 GB:

我們將提醒您在整個 AI 熱潮中我們說過的兩件事?首先,提供最佳性價比的 AI 加速器是您真正可以得到的?其次,如果它能夠以合理的精度組合進(jìn)行矩陣數(shù)學(xué)運算,并且能夠運行 PyTorch 框架和 Llama 2 或 Llama 3 模型,那么您就可以出售它,因為 Nvidia GPU 供應(yīng)不足?
但就英特爾而言,這是賺錢的機(jī)會:

在訓(xùn)練過程中,英特爾比較使用了Nvidia 的真實數(shù)據(jù)(Llama 2 7B?Llama 2 13B 和 GPT-3 175B 測試)與英特爾對 Gaudi 3 的估計值的平均值?在推理過程中,英特爾使用了Nvidia 的真實數(shù)據(jù)(Llama 2 7B?Llama 2 70B 和 Falcon 180B)與 Gaudi 3 的估計值的平均值?
如果您對這些性能/美元比率和圖表中顯示的相對性能數(shù)據(jù)進(jìn)行反向計算,那么英特爾假設(shè) Nvidia H100 加速器的成本為 23,500 美元,而如果我們對 Gaudi 3 UBB 進(jìn)行簡單的計算,則成本為 15,625 美元?
我們喜歡觀察一段時間內(nèi)的趨勢和更廣泛的峰值理論性能,以便找出誰的性價比更高?性價比更高?(它們是相反的?)因此,我們制作了一張小表格,將 Nvidia “Ampere” A100?H100 和 Blackwell B100 與英特爾 Gaudi 2 和 Gaudi 3 加速器進(jìn)行了比較,這兩款加速器都采用帶有八個加速器的基板配置?請看一下這個:
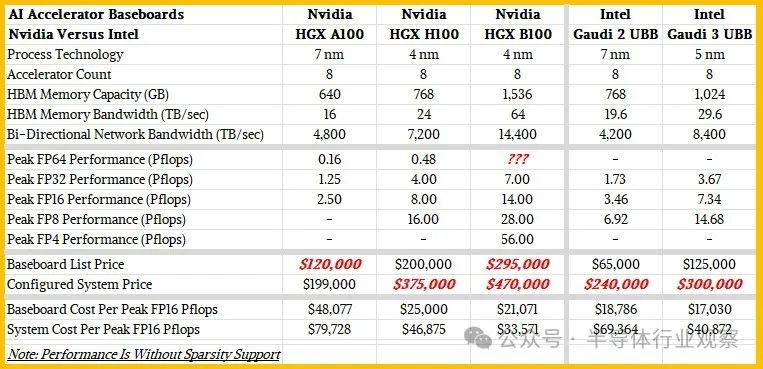
請記住,這些是八路主板的數(shù)字,而不是設(shè)備的數(shù)字,設(shè)備將成為目前大多數(shù) AI 客戶的基本計算單元?
當(dāng)然,我們完全意識到,在利用這些設(shè)備及其基板集群的計算?內(nèi)存和網(wǎng)絡(luò)方面,每個 AI 模型都有自己的獨特之處?里程肯定會因工作負(fù)載和設(shè)置而異?
我們還喜歡從系統(tǒng)的角度來思考,我們已經(jīng)估算了采用這些基板并添加雙插槽 X86 服務(wù)器綜合體的成本,該服務(wù)器綜合體具有 2 TB 主內(nèi)存?400 Gb/秒 InfiniBand 網(wǎng)卡?一對用于操作系統(tǒng)的 1.9 TB NVM-Express 閃存驅(qū)動器,以及八個 3.84 TB NVM-Express 閃存驅(qū)動器用于將本地數(shù)據(jù)存儲到 UBB?
我們的表格顯示了這五種機(jī)器的相對性價比?我們使用 FP16 精度來衡量所有這些設(shè)備,我們認(rèn)為這是比較的良好基準(zhǔn),并且設(shè)備上沒有激活任何稀疏性支持,因為并非所有矩陣和算法都可以利用這一點?如果您想自己做數(shù)學(xué)運算,可以使用較低的精度?
根據(jù)黃仁勛去年在主題演講中所說,HGX H100 基板的成本為 20 萬美元,所以我們實際上知道這個數(shù)字,這也與我們在市場上看到的完整系統(tǒng)定價一致?英特爾剛剛告訴我們,帶有八個 Gaudi 3 加速器的基板成本為 12.5 萬美元?H100 基板的額定速度為 8 千萬億次浮點運算,Gaudi 3 基板的額定速度為 7.34 千萬億次浮點運算,FP16 精度,無稀疏性?這意味著 H100 綜合體每千萬億次浮點運算的成本為 2.5 萬美元,而 Gaudi 3 每千萬億次浮點運算的成本為 17,030 美元,性價比高出 32%,對英特爾有利?
現(xiàn)在,如果你構(gòu)建一個系統(tǒng)并添加那些昂貴的 CPU?主內(nèi)存?網(wǎng)絡(luò)接口卡和本地存儲,差距就會開始縮小?按照我們上面概述的配置,Nvidia H100 系統(tǒng)的成本可能約為 375,000 美元,即每千萬億次浮點運算 46,875 美元?具有相同配置的 Gaudi 3 系統(tǒng)的成本約為 300,000 美元,每千萬億次浮點運算的成本為 40,872 美元?這僅比 Nvidia 系統(tǒng)高出 12.8% 的性價比?
如果添加相同的交換?支持?電力?環(huán)境和管理成本,那么差距就會變得更小?
因此,請從系統(tǒng)級別思考,并對您自己的模型和應(yīng)用程序進(jìn)行自己的基準(zhǔn)測試?
現(xiàn)在,最后一件事:讓我們談?wù)動⑻貭?Gaudi 3 的收入和渠道?如果你算一下,5 億美元只是 4,000 塊基板和 32,000 個 Gaudi 3 加速器?而 Gaudi 渠道中剩余的 15 億美元幾乎肯定全部用于可能銷售 Gaudi 3 設(shè)備 - 而不是未完成的銷售積壓,因此絕對不是包里的貓 - 并且僅代表銷售 12,000 塊基板和總共 96,000 個加速器的機(jī)會?Nvidia 今年將銷售數(shù)百萬個數(shù)據(jù)中心 GPU,雖然其中許多不會是 H100?H200?B100 和 B200,但其中許多將是?